
Simple Machine Translation Using LSTMs
This is a simple example of machine translation using LSTMs with TensorFlow 2. I follow the guide here with minor modifications to get it up an running on Google Colab, primarily move from TensorFlow 1.x to 2.x.
The example is all about gathering input in German and translating it to English. I’ve omitted some output lines where my names pop in the folder structure and so on :)
Get data if not done already!
!mkdir -p data
%cd data
!wget http://www.manythings.org/anki/deu-eng.zip
--2020-02-09 22:47:07-- http://www.manythings.org/anki/deu-eng.zip
Resolving www.manythings.org (www.manythings.org)... 104.24.108.196, 104.24.109.196, 2606:4700:3037::6818:6cc4, ...
Connecting to www.manythings.org (www.manythings.org)|104.24.108.196|:80... connected.
HTTP request sent, awaiting response... 200 OK
Length: 7747747 (7.4M) [application/zip]
Saving to: ‘deu-eng.zip’
deu-eng.zip 100%[===================>] 7.39M 4.47MB/s in 1.7s
2020-02-09 22:47:09 (4.47 MB/s) - ‘deu-eng.zip’ saved [7747747/7747747]
!unzip deu-eng.zip
Archive: deu-eng.zip
inflating: deu.txt
inflating: _about.txt
!ls -lrt
%cd ..
total 38797
-rw------- 1 root root 7747747 Jan 11 14:49 deu-eng.zip
-rw------- 1 root root 31978057 Jan 11 23:49 deu.txt
-rw------- 1 root root 1441 Jan 11 23:49 _about.txt
/content/drive/My Drive/Projects-Scratchpad/NLP/German-To-English-MT
Upgrade to TensorFlow 2
!pip uninstall tensorflow
Uninstalling tensorflow-1.15.0:
Would remove:
/usr/local/bin/estimator_ckpt_converter
/usr/local/bin/freeze_graph
/usr/local/bin/saved_model_cli
/usr/local/bin/tensorboard
/usr/local/bin/tf_upgrade_v2
/usr/local/bin/tflite_convert
/usr/local/bin/toco
/usr/local/bin/toco_from_protos
/usr/local/lib/python3.6/dist-packages/tensorflow-1.15.0.dist-info/*
/usr/local/lib/python3.6/dist-packages/tensorflow/*
/usr/local/lib/python3.6/dist-packages/tensorflow_core/*
Proceed (y/n)? y
Successfully uninstalled tensorflow-1.15.0
!pip install tensorflow
Collecting tensorflow
[?25l Downloading https://files.pythonhosted.org/packages/85/d4/c0cd1057b331bc38b65478302114194bd8e1b9c2bbc06e300935c0e93d90/tensorflow-2.1.0-cp36-cp36m-manylinux2010_x86_64.whl (421.8MB)
[K |████████████████████████████████| 421.8MB 42kB/s
[?25hRequirement already satisfied: gast==0.2.2 in /usr/local/lib/python3.6/dist-packages (from tensorflow) (0.2.2)
...
SKIPPING AS THESE LINES DO NOT ADD VALUE! LOOK FOR SUCCESS AT THE END!
...
Successfully installed tensorboard-2.1.0 tensorflow-2.1.0 tensorflow-estimator-2.1.0
Lets get started!
import string
import re
from numpy import array, argmax, random, take
import pandas as pd
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, LSTM, Embedding, RepeatVector
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.callbacks import ModelCheckpoint
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.models import load_model
from tensorflow.keras import optimizers
import matplotlib.pyplot as plt
print(tf.__version__)
%matplotlib inline
pd.set_option('display.max_colwidth', 200)
2.1.0
# function to read raw text file
def read_text(filename):
# open the file
file = open(filename, mode='rt', encoding='utf-8')
# read all text
text = file.read()
file.close()
return text
# split a text into sentences
def to_lines(text):
sents = text.strip().split('\n')
sents = [i.split('\t') for i in sents]
return sents
data = read_text("data/deu.txt")
deu_eng = to_lines(data)
deu_eng = array(deu_eng)
deu_eng
array([['Hi.', 'Hallo!',
'CC-BY 2.0 (France) Attribution: tatoeba.org #538123 (CM) & #380701 (cburgmer)'],
['Hi.', 'Grüß Gott!',
'CC-BY 2.0 (France) Attribution: tatoeba.org #538123 (CM) & #659813 (Esperantostern)'],
['Run!', 'Lauf!',
'CC-BY 2.0 (France) Attribution: tatoeba.org #906328 (papabear) & #941078 (Fingerhut)'],
...,
["If someone who doesn't know your background says that you sound like a native speaker, it means they probably noticed something about your speaking that made them realize you weren't a native speaker. In other words, you don't really sound like a native speaker.",
'Wenn jemand Fremdes dir sagt, dass du dich wie ein Muttersprachler anhörst, bedeutet das wahrscheinlich: Er hat etwas an deinem Sprechen bemerkt, dass dich als Nicht-Muttersprachler verraten hat. Mit anderen Worten: Du hörst dich nicht wirklich wie ein Muttersprachler an.',
'CC-BY 2.0 (France) Attribution: tatoeba.org #953936 (CK) & #3807493 (Tickler)'],
['It may be impossible to get a completely error-free corpus due to the nature of this kind of collaborative effort. However, if we encourage members to contribute sentences in their own languages rather than experiment in languages they are learning, we might be able to minimize errors.',
'Es ist wohl unmöglich, einen vollkommen fehlerfreien Korpus zu erreichen\xa0— das liegt in der Natur eines solchen Gemeinschaftsprojekts. Doch wenn wir unsere Mitglieder dazu bringen können, nicht mit Sprachen herumzuexperimentieren, die sie gerade lernen, sondern Sätze in ihrer eigenen Muttersprache beizutragen, dann gelingt es uns vielleicht, die Zahl der Fehler klein zu halten.',
'CC-BY 2.0 (France) Attribution: tatoeba.org #2024159 (CK) & #2174272 (Pfirsichbaeumchen)'],
['Doubtless there exists in this world precisely the right woman for any given man to marry and vice versa; but when you consider that a human being has the opportunity of being acquainted with only a few hundred people, and out of the few hundred that there are but a dozen or less whom he knows intimately, and out of the dozen, one or two friends at most, it will easily be seen, when we remember the number of millions who inhabit this world, that probably, since the earth was created, the right man has never yet met the right woman.',
'Ohne Zweifel findet sich auf dieser Welt zu jedem Mann genau die richtige Ehefrau und umgekehrt; wenn man jedoch in Betracht zieht, dass ein Mensch nur Gelegenheit hat, mit ein paar hundert anderen bekannt zu sein, von denen ihm nur ein Dutzend oder weniger nahesteht, darunter höchstens ein oder zwei Freunde, dann erahnt man eingedenk der Millionen Einwohner dieser Welt\xa0leicht, dass seit Erschaffung ebenderselben wohl noch nie der richtige Mann der richtigen Frau begegnet ist.',
'CC-BY 2.0 (France) Attribution: tatoeba.org #7697649 (RM) & #7729416 (Pfirsichbaeumchen)']],
dtype='<U537')
# Take limited rows depending upon compute!
# deu_eng = deu_eng[:50000,:]
# Remove attribution field
deu_eng = deu_eng[:, :2]
# Remove punctuation
deu_eng[:,0] = [s.translate(str.maketrans('', '', string.punctuation)) for s in deu_eng[:,0]]
deu_eng[:,1] = [s.translate(str.maketrans('', '', string.punctuation)) for s in deu_eng[:,1]]
deu_eng
array([['Hi', 'Hallo'],
['Hi', 'Grüß Gott'],
['Run', 'Lauf'],
...,
['If someone who doesnt know your background says that you sound like a native speaker it means they probably noticed something about your speaking that made them realize you werent a native speaker In other words you dont really sound like a native speaker',
'Wenn jemand Fremdes dir sagt dass du dich wie ein Muttersprachler anhörst bedeutet das wahrscheinlich Er hat etwas an deinem Sprechen bemerkt dass dich als NichtMuttersprachler verraten hat Mit anderen Worten Du hörst dich nicht wirklich wie ein Muttersprachler an'],
['It may be impossible to get a completely errorfree corpus due to the nature of this kind of collaborative effort However if we encourage members to contribute sentences in their own languages rather than experiment in languages they are learning we might be able to minimize errors',
'Es ist wohl unmöglich einen vollkommen fehlerfreien Korpus zu erreichen\xa0— das liegt in der Natur eines solchen Gemeinschaftsprojekts Doch wenn wir unsere Mitglieder dazu bringen können nicht mit Sprachen herumzuexperimentieren die sie gerade lernen sondern Sätze in ihrer eigenen Muttersprache beizutragen dann gelingt es uns vielleicht die Zahl der Fehler klein zu halten'],
['Doubtless there exists in this world precisely the right woman for any given man to marry and vice versa but when you consider that a human being has the opportunity of being acquainted with only a few hundred people and out of the few hundred that there are but a dozen or less whom he knows intimately and out of the dozen one or two friends at most it will easily be seen when we remember the number of millions who inhabit this world that probably since the earth was created the right man has never yet met the right woman',
'Ohne Zweifel findet sich auf dieser Welt zu jedem Mann genau die richtige Ehefrau und umgekehrt wenn man jedoch in Betracht zieht dass ein Mensch nur Gelegenheit hat mit ein paar hundert anderen bekannt zu sein von denen ihm nur ein Dutzend oder weniger nahesteht darunter höchstens ein oder zwei Freunde dann erahnt man eingedenk der Millionen Einwohner dieser Welt\xa0leicht dass seit Erschaffung ebenderselben wohl noch nie der richtige Mann der richtigen Frau begegnet ist']],
dtype='<U537')
# convert text to lowercase
for i in range(len(deu_eng)):
deu_eng[i,0] = deu_eng[i,0].lower()
deu_eng[i,1] = deu_eng[i,1].lower()
deu_eng
array([['hi', 'hallo'],
['hi', 'grüß gott'],
['run', 'lauf'],
...,
['if someone who doesnt know your background says that you sound like a native speaker it means they probably noticed something about your speaking that made them realize you werent a native speaker in other words you dont really sound like a native speaker',
'wenn jemand fremdes dir sagt dass du dich wie ein muttersprachler anhörst bedeutet das wahrscheinlich er hat etwas an deinem sprechen bemerkt dass dich als nichtmuttersprachler verraten hat mit anderen worten du hörst dich nicht wirklich wie ein muttersprachler an'],
['it may be impossible to get a completely errorfree corpus due to the nature of this kind of collaborative effort however if we encourage members to contribute sentences in their own languages rather than experiment in languages they are learning we might be able to minimize errors',
'es ist wohl unmöglich einen vollkommen fehlerfreien korpus zu erreichen\xa0— das liegt in der natur eines solchen gemeinschaftsprojekts doch wenn wir unsere mitglieder dazu bringen können nicht mit sprachen herumzuexperimentieren die sie gerade lernen sondern sätze in ihrer eigenen muttersprache beizutragen dann gelingt es uns vielleicht die zahl der fehler klein zu halten'],
['doubtless there exists in this world precisely the right woman for any given man to marry and vice versa but when you consider that a human being has the opportunity of being acquainted with only a few hundred people and out of the few hundred that there are but a dozen or less whom he knows intimately and out of the dozen one or two friends at most it will easily be seen when we remember the number of millions who inhabit this world that probably since the earth was created the right man has never yet met the right woman',
'ohne zweifel findet sich auf dieser welt zu jedem mann genau die richtige ehefrau und umgekehrt wenn man jedoch in betracht zieht dass ein mensch nur gelegenheit hat mit ein paar hundert anderen bekannt zu sein von denen ihm nur ein dutzend oder weniger nahesteht darunter höchstens ein oder zwei freunde dann erahnt man eingedenk der millionen einwohner dieser welt\xa0leicht dass seit erschaffung ebenderselben wohl noch nie der richtige mann der richtigen frau begegnet ist']],
dtype='<U537')
# empty lists
eng_l = []
deu_l = []
# populate the lists with sentence lengths
for i in deu_eng[:,0]:
eng_l.append(len(i.split()))
for i in deu_eng[:,1]:
deu_l.append(len(i.split()))
length_df = pd.DataFrame({'eng':eng_l, 'deu':deu_l})
length_df.hist(bins = 30)
plt.show()
# function to build a tokenizer
def tokenization(lines):
tokenizer = Tokenizer()
tokenizer.fit_on_texts(lines)
return tokenizer
# prepare english tokenizer
eng_tokenizer = tokenization(deu_eng[:, 0])
eng_vocab_size = len(eng_tokenizer.word_index) + 1
eng_length = 8
print('English Vocabulary Size: %d' % eng_vocab_size)
English Vocabulary Size: 16380
# prepare Deutch tokenizer
deu_tokenizer = tokenization(deu_eng[:, 1])
deu_vocab_size = len(deu_tokenizer.word_index) + 1
deu_length = 8
print('Deutch Vocabulary Size: %d' % deu_vocab_size)
Deutch Vocabulary Size: 35442
# encode and pad sequences
def encode_sequences(tokenizer, length, lines):
# integer encode sequences
seq = tokenizer.texts_to_sequences(lines)
# pad sequences with 0 values
seq = pad_sequences(seq, maxlen=length, padding='post')
return seq
from sklearn.model_selection import train_test_split
# split data into train and test set
train, test = train_test_split(deu_eng, test_size=0.2, random_state = 12)
# prepare training data
trainX = encode_sequences(deu_tokenizer, deu_length, train[:, 1])
trainY = encode_sequences(eng_tokenizer, eng_length, train[:, 0])
# prepare validation data
testX = encode_sequences(deu_tokenizer, deu_length, test[:, 1])
testY = encode_sequences(eng_tokenizer, eng_length, test[:, 0])
# build NMT model
def define_model(in_vocab,out_vocab, in_timesteps,out_timesteps,units):
model = Sequential()
model.add(Embedding(in_vocab, units, input_length=in_timesteps, mask_zero=True))
model.add(LSTM(units))
model.add(RepeatVector(out_timesteps))
model.add(LSTM(units, return_sequences=True))
model.add(Dense(out_vocab, activation='softmax'))
return model
# model compilation
model = define_model(deu_vocab_size, eng_vocab_size, deu_length, eng_length, 512)
rms = optimizers.RMSprop(lr=0.001)
model.compile(optimizer=rms, loss='sparse_categorical_crossentropy')
filename = 'model.h1.09_02_19.h5'
checkpoint = ModelCheckpoint(filename, monitor='val_loss', verbose=1, save_best_only=True, mode='min')
# train model
history = model.fit(trainX, trainY.reshape(trainY.shape[0], trainY.shape[1], 1),
epochs=30, batch_size=512, validation_split = 0.2, callbacks=[checkpoint],
verbose=1)
Train on 130927 samples, validate on 32732 samples
Epoch 1/30
130560/130927 [============================>.] - ETA: 0s - loss: 4.8970
Epoch 00001: val_loss improved from inf to 4.58372, saving model to model.h1.09_02_19.h5
130927/130927 [==============================] - 55s 418us/sample - loss: 4.8961 - val_loss: 4.5837
Epoch 2/30
130560/130927 [============================>.] - ETA: 0s - loss: 4.2704
Epoch 00002: val_loss improved from 4.58372 to 4.05572, saving model to model.h1.09_02_19.h5
130927/130927 [==============================] - 42s 318us/sample - loss: 4.2700 - val_loss: 4.0557
Epoch 3/30
130560/130927 [============================>.] - ETA: 0s - loss: 3.8345
Epoch 00003: val_loss improved from 4.05572 to 3.68000, saving model to model.h1.09_02_19.h5
130927/130927 [==============================] - 41s 310us/sample - loss: 3.8343 - val_loss: 3.6800
...
SKIPPING AS THESE LINES DO NOT ADD VALUE! THIS GOES ON FOR 30 EPOCHS!
...
Epoch 29/30
130560/130927 [============================>.] - ETA: 0s - loss: 0.5539
Epoch 00029: val_loss did not improve from 2.35177
130927/130927 [==============================] - 37s 285us/sample - loss: 0.5539 - val_loss: 2.7105
Epoch 30/30
130560/130927 [============================>.] - ETA: 0s - loss: 0.5171
Epoch 00030: val_loss did not improve from 2.35177
130927/130927 [==============================] - 37s 286us/sample - loss: 0.5172 - val_loss: 2.7329
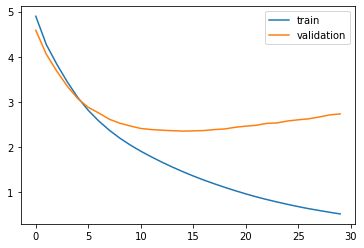
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.legend(['train','validation'])
plt.show()
model = load_model('model.h1.09_02_19.h5')
preds = model.predict_classes(testX.reshape((testX.shape[0],testX.shape[1])))
def get_word(n, tokenizer):
for word, index in tokenizer.word_index.items():
if index == n:
return word
return None
preds_text = []
for i in preds:
temp = []
for j in range(len(i)):
t = get_word(i[j], eng_tokenizer)
if j > 0:
if (t == get_word(i[j-1], eng_tokenizer)) or (t == None):
temp.append('')
else:
temp.append(t)
else:
if(t == None):
temp.append('')
else:
temp.append(t)
preds_text.append(' '.join(temp))
pred_df = pd.DataFrame({'actual' : test[:,0], 'predicted' : preds_text})
# print 15 rows randomly
pred_df.sample(15)
| actual | predicted | |
|---|---|---|
| 15911 | a computer is an absolute necessity now | here are examination for today |
| 34174 | i doubt that tom has the courage to do what really needs to be done | tom the what to do |
| 21969 | tom is helping mary | tom helping mary |
| 35742 | you can read this book | you can read this book |
| 11557 | she gave him a good kick | she gave him a there |
| 37967 | they hired tom | tom became been |
| 18934 | they didnt even know themselves | you didnt even before |
| 32938 | tom teaches french to my children | tom teaches my children |
| 22722 | tom was troubled by what happened | tom was about the what happened |
| 25676 | are you certain youve made the right decision | are you sure youve wrong the decision |
| 11464 | she is interested in music | she is long |
| 9202 | would you like to go to a movie | do you want to go the |
| 33416 | tom is likely to forget his promise | tom will forget promise |
| 14617 | please add tom to the list | please write on list |
| 5493 | tom often wears a fake wedding ring | tom has an on |
We saw a quick sample of how to work with TensorFlow 2.x for simple machine translation task. The example is really basic, the pre-processing techniques and the model as well. The inaccuracies are huge as you can see the above table. It is a good starting point though for understanding a general pipeline, maybe?
Thanks for reading! :)